实证研究数据处理的过程标准化探索
Published:
写在前面 (2025-7-22)
这个频道的出发点是,记录下我处理GLOC_24眼动实验数据的全过程。通过观察、分解数据处理、建模的全过程,描绘出一个可拓展到同类实证研究的R代码框架。概览的思路是:
- 数据导入、清洗 –>
- 筛选出需要的列数据,整理排列为标签完整的行、列数据 –>
- 针对各个研究问题,存储各自所需数据的完整数据框 –>
- 根据自变量、因变量的数据性质,划分几种主流的线性模型构建方法。每个方法包括数据的描述性统计、分布分析、固定和随机效应变量确认、初步拟合、拟合优度检验、数据变换、再次拟合、对比拟合优度、输出较优模型的统计结果。–>
- 制图,使用 ggplot,根据数据特性,制作有区分度的图表。后期调整重点是比例、坐标轴值域、配色外观等。–>
- 统计结果和制图的公式保存、结果输出,且全流程保存为 rmd 文档,写明过程,以便回溯。
这个概览的思路是和以前实验数据处理一脉相承的事情,虽然繁琐,但是并不陌生。然而这次想做的过程标准化探索,是借助AI大模型的力量,对已有的流程再做一次结构化处理。思路1:以工作流为基础,构建出帮助处理数据的智能体,以AI agent 为重要辅助,核心是搭建工作流和调用 LLM;思路2:以数据处理的逻辑块为基础,构建出半固定的流程界面,将AI 辅助固定在具体的任务上,目标产品是可视化的交互式网站界面,用户可以直接上传所有实验数据,在流程的引导下,半自动地描述数据、选择处理选项,完成全流程。
思路2 是我更想做到的,一个类似于“傻瓜式”的一站式数据处理网站,极大地有利于翻译实证研究者快速得出实验结果。这种形式的前驱是 Michael 那一套 Translog 数据放在 YAWAT 平台上一键导出的效果,但是 YAWAT 的数据是直接从 Translog 导出的,因此数据是从闭源到开源。而思路2想做的是从半开源(需要符合一定的数据特性,再加以描述)到闭源的效果。Translog 和 YAWAT 的缺点很明显,从数据报错到手工对齐的繁琐,再到导出的半原始数据,都造成了很多的不方便。我想做的新工具不见得能实际上产生更好的效果,但是,试一试吧,谁知道呢?
眼动研究数据处理全流程 Overview
这一节是对于眼动数据处理全流程的梳理:
使用 NotebookLM 制作了流程的讨论对话,用来加深印象。
和 Claude 聊了一下,把原始数据类型列出来,并给出处理思路,再导入到 napkin 中生成一个脑图,如下。
Part 1 数据导入与预处理
- 环境配置
- 设置系统区域设置(
Sys.setlocale('LC_ALL', 'Chinese')) - 设置工作目录
- 加载必要的R包(数据处理包、统计分析包、可视化包等)
- 加载自定义函数(如
readTobiiTables.R)
- 设置系统区域设置(
- 原始数据导入
- 导入眼动数据(使用
readFixationSummary函数处理Tobii导出的数据) - 导入按键数据(keystroke数据,使用
calcKeystroke函数) - 导入NASA认知负荷量表数据
- 导入翻译产品(译文)数据
- 导入眼动数据(使用
- 数据合并
- 将眼动数据和按键数据合并
- 将合并后的数据与NASA评分结合
- 添加必要的列标识符(如参与者ID、文本类型、通道等)
- 将处理后的眼动列数据整合到一个数据框中
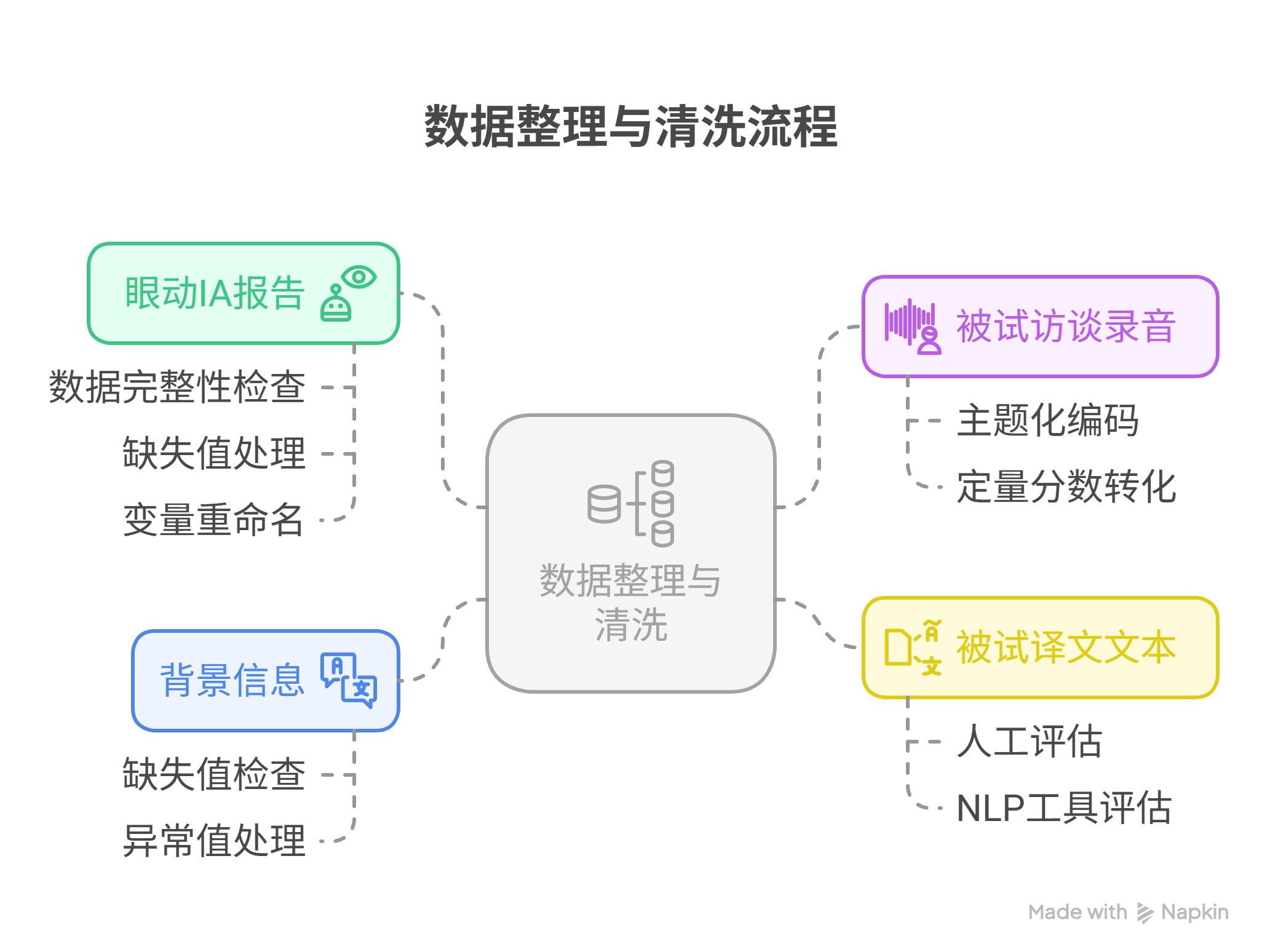
在2024年12月整月收集的GLOC_24实验的实证数据,主要分为以下四类:
- 眼动IA report (Eyelink导出):包含每个被试、每个试次、每个兴趣区(IA)的汇总指标,如注视时长、首次注视时间等。
- 被试访谈录音 (已转为文字):包含被试的主观反馈,如困难度、策略描述等。
- 被试译文文本:可用于评估翻译质量。
- 被试背景信息文件 (Excel表格):包含人口学信息、语言水平等。
第一类的眼动兴趣区数据是其中最核心、影响实验结果的。通常可以最快出结果(按照常规的混合效应线性模型构建方法),决定研究问题是否被验证,是否出了显著性结果。
第二类是被试主观数据、译文质量。这两类数据的处理,以往需要非常多的手动工作,因此旷日持久,且结果不一定显著。但是,今年这次的流程创新有可能可以解决这个问题。一方面是效率提高——访谈录音可以自动转录,且用统一标签的方法,快速提取有效信息,过程中可以使用LLM来协助;另一方面译文质量的评估,以往是个老大难问题。因为翻译专家对译文的评估,即使基于同一个标准,比如 MQM, FAR等专业质量评估框架,个体的主观性往往非常强,很难形成较高的评分者信度。所以,今年也许可以尝试COMET等人工智能辅助评分的方法,让人工智能用统一的方法来评估质量。即使大概率会被质疑,但是效率、质量的平衡和统一,一定会有价值和意义。
Part 2 数据清洗与转换
- 异常数据处理
- 移除不正确的响应数据(如脚本中移除了特定的会话:P14_H01_double, P18_H02_double等)
- 移除不准确的会话数据
- 数据分区
- 根据研究问题(RQ1、RQ2)分隔数据
- 根据文本类型(H文本、V文本)分隔数据
- 根据翻译经验(专业/新手)分隔数据
- 创建兴趣区域(AOI)分析数据框
- 将ST(源文本)、TT(目标文本)、视频区域数据整合
- 计算各兴趣区域的注视百分比
为进行混合效应模型分析,需要将清洗后的多源数据整合到一张主表中。
目标形式:
- 混合效应模型通常每一行是一次被试-材料(或被试-材料-区域,依据分析层级)的观测。
- 核心变量包括:Subject(被试ID)、Text(材料/句子/段落ID)、Task (任务类型)、IA(如果按区域分析)、关键眼动指标(因变量)、以及协变量(如背景信息、访谈评分、译文评分等)。
整合方法:
- 主表结构选择:以‘被试-材料-IA’为主键,一份长表。
- 主表来源:以眼动IA report清洗得到的表为基础,因为它包含了最细致的观测层级。
- 数据合并:
- 对于被试级别的数据(如背景信息、访谈评分),使用Subject作为匹配键进行合并(merge)。
- 对于材料级别的数据(如译文评分),使用Subject-Item作为匹配键进行合并。
- 预期总表结构:
Subject Text Task IA GazeDuration … Accuracy Fluency InterviewDifficulty LanguageLevel 流程小结:
- 逐份数据文件清理、整理成长表结构。
- 用merge/join的方式合并为一份总表,确保主分析变量全部齐全。
- 对关键分析维度进行检查(如每个被试、每个材料在每个IA下是否都齐全)。
- 变量标准化/正态变换(如必要),为选择合适的混合效应模型做最后准备。
Part 3 统计建模与分析
- 描述性统计
- 查看各变量的描述性统计指标
- 检查数据分布情况
- 构建统计模型
- 线性混合模型(lmer)用于连续变量
- 广义线性混合模型(glmer)用于计数数据(泊松分布、负二项分布)
- 对正态性和离散性的检验与调整
- 模型评估与优化
- 对比不同模型(AIC、R²、离散性)
- 进行数据转换(如log转换)以满足模型假设
Part 4 结果可视化与输出
- 结果可视化
- 绘制预测效应图
- 创建比较图表(如箱线图、直方图)
- 组合多图展示
- 结果汇总与保存
- 输出统计模型结果表
- 保存图表和数据
总结AVT21中的数据清洗、整理、建模、输出过程
I. AVT21的数据清洗和整理
A. 数据清洗
- 异常值处理
- 通过
excludeOutlier函数移除离群值,基于z-score方法(> 2.5标准差) - 脚本中使用如下代码移除特定的错误响应:
process_clean <- process_all[-c(which(process_all$Label == "P14_H01_double"), which(process_all$Label == "P18_H02_double"), which(process_all$Label == "P22_H02_single"), which(process_all$Label == "P07_H01_double"), which(process_all$Label == "P26_H01_single")),]
- 通过
- 缺失值处理
- 设置默认值(如单轨道条件下视频区域的注视时长设为0)
FixationCols$FixNum_Video[which(FixationCols$Channel == "single")] <- 0 FixationCols$FixDur_Video[which(FixationCols$Channel == "single")] <- 0
- 设置默认值(如单轨道条件下视频区域的注视时长设为0)
- 数据分类与标记
- 根据参与者专业程度分组
RQ1_pro <- RQ1_data[c(which(RQ1_data$Part == "P04"), which(RQ1_data$Part == "P06"),...),] RQ1_nov <- RQ1_data[-c(which(RQ1_data$Part == "P04"), which(RQ1_data$Part == "P06"),...),] - 添加文本类型标签
RQ1_data$Text_type[which(RQ1_data$Text_type == "H")] <- "Talking head\n(high level)"
- 根据参与者专业程度分组
B. 数据框整理
- 计算关键指标
- 总注视时长与注视点计算
FixationCols$TotalFixDur <- FixationCols$FixDur_ST + FixationCols$FixDur_TT + FixationCols$FixDur_Video FixationCols$TotalFixNum <- FixationCols$FixNum_ST + FixationCols$FixNum_TT + FixationCols$FixNum_Video - 计算平均注视时长
FixationCols$AvgFixDur <- FixationCols$TotalFixDur/FixationCols$TotalFixNum - 计算各兴趣区域的注视百分比
FixationCols$Ratio_ST_Fix_dur <- FixationCols$FixDur_ST/FixationCols$TotalFixDur
- 总注视时长与注视点计算
- 数据转换为长格式用于可视化
AOI_summary <- pivot_longer(process_clean[,c(1:4,10:12)], cols = c("FixDur_ST", "FixDur_TT", "FixDur_Video"), names_to = "AOI", values_to = c("FixDur")) - 数据过滤
- 根据研究问题过滤数据
RQ1_data <- process_clean[which(process_clean$Channel == "double"),] RQ2_data <- process_clean[which(process_clean$Text_type == "H"),]
- 根据研究问题过滤数据
C. 数据准备
- 计算多种眼动指标
- 注视时长
- 注视次数
- 平均注视时长
- 注视时长占比
- 注视次数占比
- 计算按键指标
- 总按键次数
- 插入次数(Insertion)
- 删除次数(Deletion)
- 暂停次数与时长(阈值:300ms, 1000ms)
- 数据整合
- 将眼动数据、按键数据和NASA评分整合
II. AVT21的统计建模与数据分析
Step 1. 数据特征分析
- 分布检验
- 使用
shapiro.test检验数据是否符合正态分布 - 检查直方图识别分布形状
- 使用箱线图检测离群值
- 使用
- 数据转换
- 对非正态分布数据进行log转换
TotalFixDur_2 <- lmer(log(TotalFixDur) ~ Text_type + (1|Part), data = RQ1_data) - 使用Box-Cox转换寻找最优变换参数
TotalFixDur_box <- optim.boxcox(TotalFixDur_0, data = RQ1_data, find.in.range = c(-2,2))
- 对非正态分布数据进行log转换
Step 2. 模型构建
- 线性混合模型(连续型因变量)
- 对注视时长等连续型数据使用lmer模型
TotalFixDur_1 <- lmer(TotalFixDur ~ Text_type + (1|Part), data = RQ1_data) - 加入随机效应考虑参与者差异
RQ2_AvgFixDur_2 <- lmer(TotalFixDur/TotalFixNum ~ Channel + (1|Part) + (1|Text_ID), data = RQ2_data)
- 对注视时长等连续型数据使用lmer模型
- 广义线性混合模型(计数型因变量)
- 对注视次数等计数数据尝试泊松分布
TotalFixNum_glm_1 <- glmer(TotalFixNum ~Text_type + (1|Part), data = RQ1_data, family = poisson()) - 考虑过离散问题,采用负二项分布
TotalFixNum_glm_2 <- glmer.nb(TotalFixNum ~Text_type + (1|Part), data = RQ1_data)
- 对注视次数等计数数据尝试泊松分布
- 模型检验与选择
- 使用simulateResiduals检验离散性
sim_TotalFixNum_glm_1 <- simulateResiduals(TotalFixNum_glm_1, refit=T) testDispersion(sim_TotalFixNum_glm_1, plot = T) - 比较AIC/BIC值选择最优模型
tab_model(TotalFixDur_1, show.aic=T, show.stat = T) tab_model(TotalFixDur_2, show.aic=T, show.stat = T)
- 使用simulateResiduals检验离散性
Step 3. 效应检验
- 主效应与交互效应
- 检验文本类型效应
- 检验通道效应(单模态vs多模态)
- 检验文本类型与通道的交互效应
- 事后检验
- 使用emmeans进行简单效应分析
pairs(emmeans(RQ2_fixdur_ST_all_2, ~ Channel | Text_type))
- 使用emmeans进行简单效应分析
III. AVT21的数据输出与可视化
Step 1. 统计结果输出
- 表格输出
- 使用tab_model函数生成模型统计表
tab_model(TotalFixDur_2, show.df = T, show.se = T, show.aic=T, show.stat = T) - 使用kable和kableExtra包格式化表格
save_kable(kable(RQ1_describe,format = "html", booktabs = TRUE) %>% kable_classic(), "../!Submission Drafts/Tables/RQ1_summary.html", bs_theme= "simplex")
- 使用tab_model函数生成模型统计表
- 效应值提取
- 从模型中提取效应大小与显著性
FixDur_AOI_stat <- rbind(FixDur_ST_stat,FixDur_TT_stat,FixDur_video_stat) FixDur_AOI_stat[,2:7] <- round(FixDur_AOI_stat[,2:7], digits = 2)
- 从模型中提取效应大小与显著性
Step 2. 可视化
- 效应图
- 使用plot_model绘制预测效应
TotalFixDur_2_plot <- plot_model(TotalFixDur_2, type =c("pred"),terms = c("Text_type"), axis.title = c("", "TotalFixDur (s)"),title = "Total Fixation Duration")
- 使用plot_model绘制预测效应
- 描述性图表
- 箱线图展示不同条件下的数据分布
- 直方图展示数据频率分布
- 添加均值线辅助解读
RQ2_PercentDur_single <- ggplot(AOI_single_H, aes(x = AOI, y = PercentDur, fill = AOI))+ stat_boxplot(geom = "errorbar", width = 0.15) + geom_boxplot(stat = "boxplot", alpha = 0.5)
- 组合图表
- 使用grid.arrange组合多个图表
Fixation_AOI_plot <- grid.arrange(FixDur_Video_plot,FixDur_ST_plot,FixDur_TT_plot, FixNum_video_plot,FixNum_ST_plot,FixNum_TT_plot, nrow = 2, ncol = 3) - 保存高分辨率图表
ggsave("TotalFixation_plot.jpeg",TotalFixation, device="jpeg",dpi = 400, width = 6, height = 4)
- 使用grid.arrange组合多个图表
GLOC_24 数据处理进行时(以结构化为目标)
Part I. 数据导入和清理 (2025-8-2)
数据处理的dirty work
从四种数据类型入手,最先处理的是眼动数据,因为它最核心,需要非常谨慎的处理。从眼动仪导出的数据中,大致包括:眼动兴趣区报告(xls)、眼动试次报告(xls)。兴趣区报告里是注视时长、注视次数等因变量指标,或者可以进一步计算的指标。而眼动试次报告是我们要检查的第一份报告,因为它涉及到每个试次是否能够纳入到实验结果的分析中来,目的就是:排除异常试次。
A. 实验过程中的异常。本次所有40名被试,每人3个实验任务的情况下,一共产生了120个实验试次。但是并不是所有试次的所有数据都可以纳入到分析中,因为实验过程中会出现不可抗力或者其他因素导致的错误。比如,1)这次我全程作为主试参加实验,印象中至少有一次被试的全部试次都没有通过眼动校准,但是这是实验初期,我想多了解可能会出现的问题,就让被试完成了所有实验任务。但是,在数据分析中,这个被试的三个试次需要被摘除,因为在不通过校准的情况下,被试的眼动数据很可能不准确,会干扰实验结果。2)第二种情况,是不可抗力造成的数据污染。比如说,本次实验中,在不知情情况下,某场实验中,眼动仪镜头被更换,因此参数和注视点计算的结果可能会和其他试次有系统性差异,也需要排除以避免干扰。3)第三种及更多情况,包括实验中电脑故障、被试误操作未保存数据等情况,都可能会发生。这些试次需要排除在结果分析之外。
B. 眼动质量中的异常。以上都是实验过程中的异常情况。接下来,在后期数据处理时,从眼动质量指标上要进一步筛除质量差的试次,主要体现的参数是样本丢失率。以 Eyelink 1000 眼动仪为例:
眼动试次报告(trial report)中有一个直接输出的指标:VALIDATION_RESULT_RIGHT_EYE,指示被试是否通过了眼动校准。这个数据可以作为更权威的参考,来辅证主试的记录。当然,在之后的实验中,一定要记住 validation test 的重要性,每个试次都要完成。
样本丢失率 (data loss rate),或者 proportion of missing samples, 或者 sample loss rate。从眼动研究来看,常用的术语有 gaze sample percentage。如果从字面来看的话,这个“眼动样本有效率”的计算应该是 = sample_count/(duration/1000 * 采样频率)*100% 这里的duration/1000 是把一般为毫秒的时间单位换算成秒,而采样频率一般是指眼动仪一秒中可以采集多少个眼动样本点。所以分母的意思是:按照采样频率,眼动仪在该试次记录的全时长内理论上应该能收集到的样本点数量,而 sample_count 是实际采集的样本点。这就是 gaze sample percentage 的计算方法。Eyelink 上因为没有直接输出这个指标,所以可以按照这样的逻辑进行计算,单独输出一个指标。
这个指标通过初步计算,还是能得到不错的结果,所以排除异常值的效果会差一点。而另一个和眨眼相关的指标就更精确。逻辑是:因眨眼行为需要单独的计算,而因眨眼导致的样本丢失率可以排除掉更多和实验结果无关的数据点。“眨眼导致的丢失率” = (Blink_count * average_blink_duration)/Duration *100%.
样本丢失率相关的参考文献:
- Holmqvist, K., Nystrom, M., Andersson, R., Dewhurst, R., Jarodzka, H., & Weijer, J. van de. (2011). Eye-tracking: A comprehensive guide to methods and measures. Oxford. (大意是: data loss 的标准暂不统一,但是丢失率越低越好,如果有丢失率,有些也是可以解释的,因为实验设备、经验、人员等。选择 data loss 的标准研究者可以自行 argue)
- Komogortsev, O. V., Gobert, D. V., Jayarathna, S., Koh, D. H., & Gowda, S. M. (2010). Standardization of automated analyses of oculomotor fixation and saccadic behaviors. IEEE Transactions on Biomedical Engineering, 57(11), 2635–2645. (上个文献提到的一个选择样本丢失率的例子,虽然我没找到他怎么定义的样本丢失率)
呈现在论文中的清理逻辑
在描述数据清理的步骤和思路时,可以按照这样的逻辑:
实验前设备校准与验证:目的是确保空间精度,保证注视点位置准确性。标准有眼动仪设备的校准精度、被试与设备的距离控制等。
参考文献:”…the participants sat in a fixed chair, so that they would not easily move about and potentially increase the distance to the monitor (they were seated between 55 cm and 65 cm from the eye tracker).” —Hvelplund, K. T. (2011). “Allocation of cognitive resources in translation: An eye-tracking and key-logging study.” PhD thesis, Copenhagen Business School, Copenhagen, Denmark.
被试(Participant)级别的数据筛选: 目的是排除质量整体较差,或者未遵循实验指导的被试数据。标准:A. 样本丢失率(Data Loss)超过25-30%的参与者数据通常被完全排除;B. 校准精度持续超过标准阈值(calibration)的参与者数据应排除;C. 未遵循实验指导:注视模式明显异常,或者任务完成时间极端偏离(过快或过慢)。
参考文献:被试眼动质量差。”Data from ten of the translators were discarded due to poor quality of the eye-tracking data (see Section 3.5 below). The quality assessment was based on Rayner & Sereno’s observation that the average fixation during reading is 200 to 250 ms (Rayner & Sereno 1994: 58)…. 3.5 Problems with data quality… One explanation could be the equipment’s age. A discard percentage of 62.5 (data from ten out of 16 participants had to be excluded) could indicate technical problems as this figure is somewhat higher than in previous experiments carried out with the same piece of equipment (e.g. Pavlović & Jensen 2009; Jensen, in preparation).”—Jensen, K. T. H., Sjørup, A. C., & Balling, L. W. (2009). “Effects of L1 syntax on L2 translation.” Copenhagen Studies in Language, 38, 319-336.
参考文献:任务完成时间极端: “A first thing to do is to consider the exclusion of outliers. Outliers are observations that are numerically distant from the rest of the sample. An outlier can be naturally distant from the sample. For instance, a fixation may be unusually long compared to the rest of the fixations in a recording, because the participant is in fact looking at the same locale for a very long time. Although natural, this observation may not reflect the processes that we are interested in.” —Balling, L. W., & Hvelplund, K. T. (2015). “Design and Statistics in Quantitative Translation (Process) Research.” Translation Spaces, 4(1), 170-187.
试次(Trial)级别的数据筛选: 目的是排除单个试次中的低质量数据,或者受干扰、非标准执行的试次。标准:A. 单次试次中数据丢失率超过20;B. 关键兴趣区数据缺失的试次(视具体实验而定);C. 实验中出现明显中断或干扰。
参考文献:”In process-oriented studies, another important consideration in connection with data preparation has to do with the quality of eye-tracking data. Problems with eye-tracking data involve, for instance, abnormally short fixations, conspicuously few fixations in a recording or disagreement between registered fixation location and actual fixation location. Eye-tracking data quality is often not considered systematically and there is a strong risk that analyses are based on eye-tracking data that do not reflect actual cognitive processing. Thorough quality analysis is thus crucial (cf. Hvelplund 2014).” —Balling, L. W., & Hvelplund, K. T. (2015). “Design and Statistics in Quantitative Translation (Process) Research.” Translation Spaces, 4(1), 170-187.
注视点(Fixation)级别的数据筛选:目的是排除时间、空间维度的不准确记录。标准:A. 时间维度:排除过短注视(通常 < 80-100ms),临近注视点可合并(距离<1°视角,间隔<50ms),以上操作可以通过 Eyelink 配套软件在输出数据之前进行处理,若有极端情况,也可以在R里批量处理;B. 空间维度:校正空间漂移,确保注视点分配准确性。这可以在实验设计时加入 drift test, 在实验过程中实时校验。如果实验对注视点兴趣区的精度要求没那么大,也可以选择不进行空间校正。
参考文献:时间维度: “Eye move- ments were analyzed with the eye tracking software ClearView, and automatic identification of words on the basis of gaze fixations was performed using Gaze- to-Word Mapping (GWM), a tool developed under the Eye-to-IT EU project.4 A study by Dragsted and Hansen (2008) reports that the mapping performed by GWM is subject to considerable uncertainty, with detection rates (fixations mapped correctly to words) at about 80%. Jensen (2008) reports detection rates of between 65% and 75%.” —Dragsted, B. (2010). “Coordination of reading and writing processes in translation: An eye on uncharted territory.” Translation and Cognition, 15, 41-62.
参考文献:时间维度和平均注视时长的讨论:”In a study on translation directionality, Pavlovi? & Jensen (2009: 99) discarded recordings in which fixations were “abnormally short”, namely < 200 milliseconds, noting that the mean fixation duration during silent reading is around 225 milliseconds (Rayner 1998: 373). Hvelplund (2011: 106) similarly used a mean fixation duration threshold of 200 milliseconds to discriminate acceptable data from non-acceptable data, while Sjørup (2013: 105) applied a threshold of 180 milliseconds. Relying on the fixation duration alone as a quality measure is not entirely unproblematic. Mean fixation duration is a relatively crude measure, which ignores the potential difference in completeness of eye-tracking recordings. More specifically, completeness, seen as how much eye movement has been successfully recorded by the eye tracker compared to how much has not been recorded, varies between recordings as a function of various factors.” —Hvelplund, K. T. (2014). “Eye tracking and the translation process: reflections on the analysis and interpretation of eye-tracking data.” MonTI: Monografías de Traducción e Interpretación, Special Issue 1, 201-223.
在论文中呈现数据质量报告,可以按照这样的流程:1. 报告校准精度平均值与标准差,2. 报告数据丢失率平均值与范围,3. 报告筛除的参与者比例与筛除的试次比例,4. 引用所采用的数据处理标准来源, 5. 说明任何偏离标准的理由。
参考文献 1:质量指标透明报告。 “There is no standard criterion for how to select the data to discard, however. Criteria used in literature include, for instance, the percentage of zero values in the raw data samples, a high offset (poor accuracy) value during validation, a high number of events with a velocity above 800°/s, and an average fixation velocity above 15°/s (indicative of low precision). For an example of accuracy and data loss criteria, see Komogortsev, Gobert, Jayarathna, Koh, and Gowda (2010).” —Holmqvist, K., Nyström, M., Andersson, R., Dewhurst, R., Jarodzka, H., & Van de Weijer, J. (2011). “Eye tracking: A comprehensive guide to methods and measures.” Oxford University Press.
后记:经过以上步骤的清理,GLOC_24的眼动数据已经排除了四个场次的数据,分别是一个被试级别的错误(3个试次)和一个试次级别的错误(calibration未通过)。现在进入标签整理、指标计算阶段。
Part 2. 整理标签、计算指标(2025-8-5)
其实昨天就要写这个部分的,但是内心还想回避,因为数据标签总是个很麻烦的工作。既基础,又dirty, 特别要根据每次实验设备不同、导出的数据列不同、实验控制的变量不同重新调整。好吧,今天写。
在处理到计算指标的时候,就需要对实验设计中的自变量、因变量特别熟悉,因为这些直接决定要创建什么样的标签列。
从头开始捋一下数据导入所需要做的工作。本次眼动数据的核心来源是从 Eyelink 1000 plus 设备上,从 Dataviewer 中导出的 edf 源文件(眼动记录的原始文件),以及在 Dataviewer 中导出的 IA report (兴趣区报告)和 Trial report (试次报告)。这两类报告的区别在于颗粒度。
trial report 颗粒度更粗,是以每名被试的每个试次为单位,导出的比如一场翻译活动中全部的眼动数据,包括总注视时长等。比如,本次实验有 40 名被试,导出 40 个 xls 文件。而每名被试做了 3 个翻译任务,也就是 3 个试次,因此每个 xls 文件中都有 3 行数据,分别对应被试在3个试次中的总注视时长、注视次数等。这么下来,导入到 R 中的所有 trial data 行数应该是 = 40 * 3 = 120 行。
IA report 颗粒度更细,是每个试次中每个兴趣区的眼动数据。也就是说,数据行的数量应该是“试次 * 兴趣区数量”。而从眼动仪设备中导出的 IA report,同样是每名被试一个 xls 文件,但是每个文件中有 9 行(3个兴趣区)。 根据 40 名被试,每人 3 个试次,每个试次都有3个兴趣区来算,导入到 R 中的所有 IA data 行数应该是 = 40 * 3 * 3 = 360 行。
这就是 Eyelink 中“试次报告”和“兴趣区报告”导出的数据结构。在R中分别导入为 IA_raw_data 和 trial_raw_data.
接下来是数据整理,核心思路包括两个方面:1. 提取有效的数据列,有需要的可以进行转换(比如时间从毫秒到秒),2. 从已有信息中提取、计算出新的数据列,用作标签分类,或者新的数据点。
第一个方面,要提取的有效数据列包括:注视时长、注视次数等核心眼动指标,并且把 IA_DWELL_TIME, TOTAL_DWELL_TIME 这些从毫秒转换为妙。
第二个方面,创建新的数据列,其中包括标签分类列,和计算出新的数据内容列。
[1]. 标签分类列中最基础的是抽取出实验场次、兴趣区等基本信息。方法如下:
在读写进 R 中成为数据框之后,同时还可以从两个报告都有的一列数据中提取基本信息:DATA_FILE. 这里的 DATA_FILE 指的是例如 “P38A_DP.edf” 这样的 edf 文件名。而这样的文件名需要在实验开始之初就想清楚命名方法,当然 Eyelink 本身也对命名有一定的要求,印象中只允许“数字+字母+下划线”这样的组合。我在这次实验中设计的命名包括了3个核心信息:”P38”–被试序号,”A” – 区块分组(用于组间对比文本),”DP”– 任务名(用于组内区分不同的任务)。由于 DATA_FILE 这一列里这三种信息都比较好定位(使用正则表达式),所以在数据整理时,可以直接使用以下方法提取了三组信息,单独创建为新的三列数据:Participant, Group, Task.
Cursor 给出的好用的函数是:dplyr::mutate 和 dplyr::select
# mutate 是创建新列或修改已有的列,只要给出列名和内容即可。抽取信息的正则表达式是(基本可通用):
data %>% mutate(
data_file_info = str_match(DATA_FILE, "P(\\d+)([A-Z])_([A-Z0-9]+)\\.edf"),
Participant = paste0("P", data_file_info[,2]),
Group = data_file_info[,3],
Task = data_file_info[,4]
)
这些是基础的标签列,这种抽取对于每个实验来说基本是一样的。
[2].接下来,是高级的标签列创建,和实验设计中的自变量有关,需要提前准备好变量的对应关系。
比如,GLOC_24实验中,文本类型是一个自变量,分为 CS 和 DP 两个级别,所以需要新增的列就是 Text_type, 对应关系是:CS1和CS2都属于 CS, DP本身就是DP. 本实验中另一个自变量是模态,分为 video 和 no_video 两个级别,所以要新增的列是 Video, 对应关系要参照实验设计中的具体任务设置,按照区组的设计,比如 A组的 CS1 是 video 级别,而 B 组的 CS1 是 no_video 级别。将这些对应关系写到新增列的条件里,就可以快速完成数据生成。
Cursor 给出的好用的函数是:dplyr::case_when 还有 %in% 这个操作符
case_when(
条件1 ~ 结果1,
条件2 ~ 结果2,
TRUE ~ 默认结果 # 其他所有情况
)
# 实际使用为:
Text_type = case_when(
Task %in% c("CS1", "CS2") ~ "CS", # 如果Task是CS1或CS2,则为"CS"
Task == "DP" ~ "DP", # 如果Task是DP,则为"DP"
TRUE ~ NA_character_ # 其他情况为NA
)
# 很好用!